Using vision transformers for face recognition
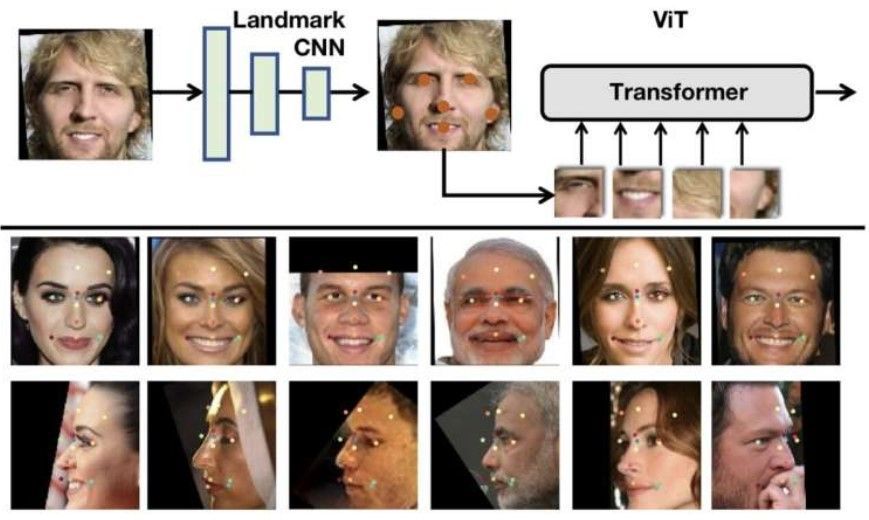
An illustration of the team's part-based visual identification system. Using a lightweight landmark CNN, a facial image is processed to produce a set of facial landmarks. Using landmarks, facial parts are sampled from the input image and are then used as input to a ViT for feature extraction and recognition. There is no landmark supervision throughout the entire process of training the system. An example of a landmark that has been detected by the landmark CNN is provided. Photo credit: Sun & Tzimiropoulos.
In addition to identifying specific individuals in images, face recognition tools also assist in identifying individuals in CCTV and video footage. In a variety of real-world settings, these tools are already being used to assist law enforcement and border control agents, as well as for authentication and biometric applications. Even though most existing models perform well, there may still be room for improvement.
A new prospective architecture for face recognition has recently been developed by researchers at Queen Mary University of London. As described in a paper pre-published on arXiv, this architecture is based on a strategy to extract facial features from images. It differs its from that used in most existing approaches.
The two researchers who conducted this study, Zhonglin Sun and Georgios Tzimiropoulos, explained to TechXplore that holistic methods utilizing convolutional neural networks (CNNs) and margin-based losses dominate face recognition research.
"Our work departs from this setting in two ways: (a) Using the Vision Transformer, we train an extremely strong baseline for face recognition called fViT, which already outperforms many state-of-the-art methods. (b) Secondly, by exploiting the Transformer's ability to process information (visual tokens) extracted from irregular grids, we devise a pipeline for face recognition that is reminiscent of part-based methods."
Face recognition approaches most widely employed are based on CNNs (a class of artificial neural networks (CNNs). It can learn automatically to recognize patterns in images, for example identifying specific objects or individuals. Even that some of these methods have achieved very high performance, recent studies suggest that another class of algorithms known as vision transformers (ViTs) may have greater potential for face recognition.
ViTs differs from CNNs in that instead of analyzing images in their entirety, they split the image into patches of a specific size. And then embed embeddings into these patches. The input data is then used in a standard transformer, a deep learning model that analyzes data differentially.
Unlike CNNs, ViTs can actually operate on patches extracted from irregular grids and do not require a uniformly spaced sampling grid as is required by convolutions," the researchers explained. Since the human face is a structured object composed of subobjects (e.g., eyes, nose, lips), we propose applying ViT to patches representing facial parts, drawing inspiration from seminal works on part-based face recognition prior to deep learning."
Sun and Tzimiropoulos developed a vision transformer architecture, dubbed part fViT, consisting of a lightweight network and a vision transformer. While the network predicts the coordinates of facial landmarks (e.g., the nose, mouth, etc. ), the transformer analyses patches containing these landmarks.
Different face transformers were trained using two well-known datasets, MS1MV3, which contains images of 93,431 people, and VGGFace2, which contains 3.1 million images and 8,600 identities. A series of tests were then conducted to evaluate their models, as well as to test how some of their features affected their performance.
For all the datasets they were tested on, their architecture achieved remarkable accuracy, comparable to that of many other state-of-the-art face recognition systems. Furthermore, their models were able to identify facial landmarks without being specifically trained.
Based on the results of this recent study, new models for face recognition based on vision transformers may be developed in the future. Additionally, the researchers' architecture could be incorporated into applications or software tools that benefit from selective analysis of different facial landmarks.
Src: Tech Xplore


Comments ()