The Types of Data Annotation and Why It’s So Important To Curate A Dataset For Specific Problems

The type of data annotation that you do can vary depending on the type of data you are inputting. There are three main types of annotation, image, video, or text. For each of these, there are many techniques that label, transcribe, process, or tag. The result marks your data so the machine learning system can identify features and recognize them in subsequent unannotated data.
This is where machine learning, or ML, begins. When data gets a label, the AI can start to classify objects or words, much like humans do as they learn. It’s what allows a machine to “see” two round objects but know that one is an orange and one is an apple. That is why the data fed into machines is so important. All of the ML solutions come up with direct results from annotated data.
Image and Video Annotation Services: The Many Different Types of Techniques Available
Image and Video annotation tracks and identifies objects within images and videos. This creates patterns for ML-based AI to learn from and predict results. The amount of raw data available in today’s world is staggering. Sifting through this data requires time and expertise, and using data annotation services will help save time.
Data annotation companies how to find the most relevant data for any predictive model. Take a look below to explore some of the most common data annotation techniques:
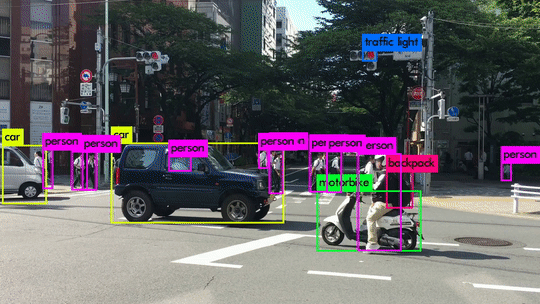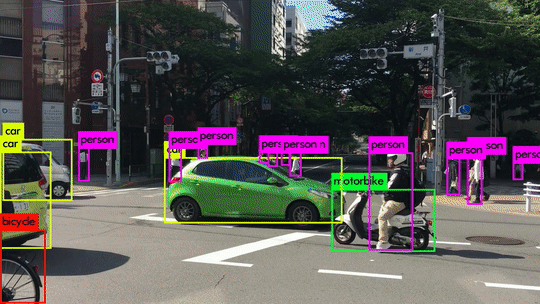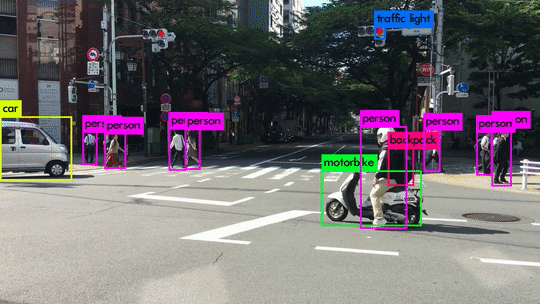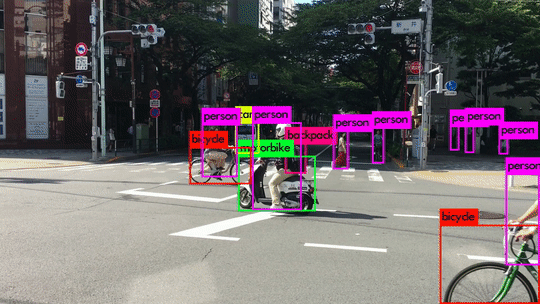
- Bounding Box Annotation: Labeling of objects within an image with “boxes.” Often used for self-driving cars to identify stoplights, pedestrians, other cars, etc. Within this annotation technique is another common sub-group, Rotated Bounding Boxes which is the same but done with objects at an angle.
- Cuboid Annotation: This is the process of labeling 2D objects with 3D cubes, which helps establish an image's depth.
- Polygon Annotation: By selecting coordinates along the edge of an object on the X and Y axis, this process maps out irregular shapes and objects.
- Skeletal Annotation: Uses lines to mark the human body, with dots at juncture points. It is used in fitness or sports models. Within Skeletal Annotation is a process called Key Point Annotation which can map out small objects by highlighting pixels as “key points” to shape the image around. This is the core of facial recognition, for example.
- Lane Annotation: Almost always used in vehicle or traffic data sets, Lane Annotation tracks the lanes on the road. It can be used to recognize lanes that are ending up ahead or an exit splitting off and is crucial in self-driving cars.
- Instance Annotation: This type of annotation involves mapping every instance of an object within an image. For example, if you used box annotation to map a person, then every person in that image is considered a variation of the same object. With instance annotation, each person in an image gets labeled as a separate “object,” allowing you to track far more specified parameters.
- Bitmask Annotation: This is the annotation to use if there is an object partially obscuring another object. With Bitmask Annotation, you connect pixels with certain objects, so if half of someone’s arm is obscured by a tree, you can link the hand and the shoulder as one “object.”
These are some of the more common annotation techniques that we can use. Keymakr has experience using one, some, or all of these techniques to make a custom annotation for highly specific datasets.
Text Annotation: How Can ML-Based AI Account For Idiosyncrasies and Context In Language
Text annotation is challenging because of the nature of language itself. As intelligent as an AI may be, it cannot intuitively grasp a common phrase such as, “it’s raining cats and dogs out there”. While a person learns this to be metaphorical, a computer will take it literally. In addition, language is constantly evolving and growing, and new slang comes and goes on a year-by-year basis. This is why text annotation is so important.
Below we’ll go over some of the most common types of text annotation. These techniques have a dramatic impact in fields such as Telecom, Healthcare, Insurance, and Banking, to name a few.
- Text Classification: This is the technique of putting chunks of text under one label. This is used in document classification or when identifying products, especially keywords for product searches.
- Sentiment Annotation: Understanding the wide range of human emotions is tricky for an ML-based AI system. That’s why this technique is so important. Human annotators go through the text and label emotions that are elicited throughout, for example, sarcasm. As this is done, the AI will look for textual clues that relate to that emotion in other texts.
- Entity Annotation: This is going through the text and assigning importance to certain entities. It can be used to identify keywords or phrases. For example, it can identify Proper Nouns, such as a specific location or person, or the grammatical label of a word.
- Entity Linking: This is an offshoot of Entity Annotation. It is used to link a repeated phrase to a specific meaning. A good example would be if someone was named Autumn, which has to be differentiated from the season throughout the text.
Because of the vast variations inherent in language, text annotation is essential. Failure to do so accurately can lead to large errors if an AI system processes a whole text dataset using the wrong language parameters.



Comments ()