Choosing the best data annotation tool for your deep learning project
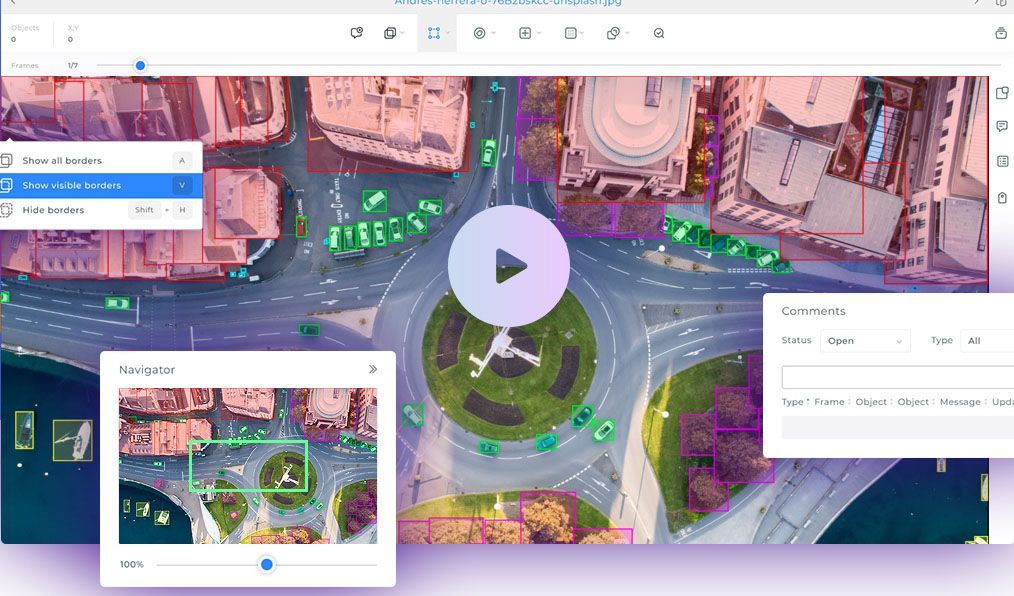
Data annotation is an important part of any deep-learning project. Training datasets determine the effectiveness of. Supervised machine learning models, in particular, require these datasets to be well-constructed. However, the kinds of tools used to create these annotated datasets vary significantly depending on your data type. Furthermore, the available technology is constantly changing too. Therefore, choosing the proper data annotation tool is essential in planning any deep learning project.
Overview of data annotation
Data annotation tools can come in many forms and functions. For example, video and image annotation require entirely different kinds of tools. There are a variety of providers for these tools as well. Some are open source. Others are software that can be subscribed to or purchased. Some exist online only, while others live on your hard drive. There are benefits and drawbacks to each. These considerations must be front and center when designing how your deep learning project will look.
What kinds of tools are available?
The kinds of tools needed for your deep learning project depend on what exactly you plan to annotate. Generally, the software used with each category focuses on specific use cases. Often, they will provide examples of how different tools have been used in the past. Although the type of metadata being annotated can vary, all deep learning projects must consider a few broad concepts. These include:
- Intention
- Data type
- Pricing
- Team structure
- Formatting
- Application type
Data annotation only works if the kinds of tools you are using align with the intentions of your project. Because there is no one-size-fits-all kind of annotation, there are a few key things that you have to think about. Some of these involve the actual capabilities of the tools, and others are more subjective. Intention can refer not only to the goals of your data project but also to the constraints you must work with. These constraints can come from various sources and may take many forms.
The most common choice that has to be made is what exactly you want to annotate. Images are a good example here because there are a lot of conceptual models with which images can be considered. Maybe you want to see what an image is. In that case, you would need to label the training dataset for general context. This can be categorized more precisely, but the goal is to identify the image as a whole. You should also identify what is in an image. This would require annotation of the internal contents of an image.
The kinds of tools used for the annotation would differ in each situation. Within each of these use cases, even more, granularity is possible. Video annotation opens up an entirely new dimension for annotating incoming data that changes over time. Textual data can be annotated not only for meaning but also for semantic context. Audio data features similar broadness in its potential textual and contextual annotations. The tools used in each situation will have overlapping but distinct features.
Outside of this, other constraints might decide which tool is being used. Pricing is a major consideration. Capability and knowledge might also be used to determine which tool is best suited for your project. The operation of these tools can vary significantly. This is magnified if you rely on distributed teams to annotate. Therefore, choosing tools that match the needs and abilities of your team is always important when designing your deep learning project. Communicating how these tools work effectively is also part of this process.
The actual formatting of the data that is being annotated also impacts the tools being used. Annotations with Microsoft’s COCO JSON format contain metadata different than Pascal’s VOX XML files. Many other kinds of file types can be used as well. Each use depends on the project and should be decided as you design it. Different tools may also have differing support for each file type. Some are proprietary to one single tool. Choosing a tool compatible with each of these formats is an essential step in this process.
Lastly, there are a few different ways that data annotation tools can be accessed. While the general processes may be similar, the action of making those choices will vary. As with anything, the other project elements will determine which is best here. Web-based annotation applications will likely serve distributed teams better. Offline, software-based ones might be able to handle larger amounts of data and more precise annotations. Again, budgeting and necessity will determine which to choose there.
Choosing the right tools for your project
Given the broad applications for data annotation, deciding which is best for your project can be a confusing process. Oftentimes, it requires strict planning from the start. Those choices can often determine what the project will look like in the end. Metadata in training datasets is only one input in your deep learning project. It’s not the sole determinant of success. It’s important to consider what other elements will be required downstream when trying to determine which tools to choose for your project.
It’s also important to consider how the metadata you create might transform over time. The development of deep learning algorithms is usually an iterative process. You monitor how well the algorithm does its assigned job and then tweak its inputs. The things that are used and the processes that are developed will need to be tweaked as well. These needed changes may be difficult to imagine at the start of the project. Having tools that can adapt to what is required over time is an essential step in this process.
In general, though, the tools best suited for your deep learning project will have to be determined through experience. What works for one team will not automatically work for all others. Whether a tool is open-source or paid, getting hands-on experience will provide the most useful information about what is needed. The robustness of these tools means you’re better off selecting for ease of use instead of feature sets. Planning and developing clear models of what you want is a much stronger strategy for success.



Comments ()