Where do autonomous driving systems get their training data?

The autonomous driving industry is one of the most promising applications of machine learning technologies. They make use of complex sources of data. These can be located on the vehicles themselves or in the surrounding environments. They can engage with real-time data or apply over time. As with any machine learning algorithm, constructing these training datasets requires the proper data annotation tools.
At its core, autonomous vehicles reflect the data used to train them. They layer these inputs to provide extremely precise movements to the vehicle. The margin for error is especially small given the high stakes of vehicles moving at speed. This means that designing the systems around these data is abnormally important. The beginning of each of these elements is properly annotating the data used to train these algorithms. Often, the kinds of annotations required will be layers on top of sources as well.
What is autonomous driving data used for?
The training data used in autonomous vehicles has applications that distinguish it from other kinds of data inputs. Autonomous vehicles are extremely complex hardware-software devices that must integrate a variety of information. If these data are not integrated properly, no single element can work properly. It is often fast-moving and very dynamic. Real-time analysis with a low threshold for error makes it one of the most unique use cases of machine learning.
The sources of the data used in autonomous driving are also unique. Image or video recognition algorithms that try to categorize objects need only to accomplish this single task. Autonomous driving operationalizes these inputs. This means that the kinds of annotation will be more specific. The kind of validation done on the incoming data must also be different. These vehicles will have to make decisions that vary depending on these precise contextual pointers. Annotation is how these can be communicated to the vehicle.
The inherent danger presented by autonomous vehicles also constrains the types of data they are able to use. Often, it is not possible to train these cars on real-world data. If a car was to make an error, for example, the consequences could impact pedestrians or other drivers. Autonomous driving vehicles make use of simulations to get around this. Many of these simulations use other machine learning systems to construct representations of the world. This can allow for testing and refinement in a controlled environment.
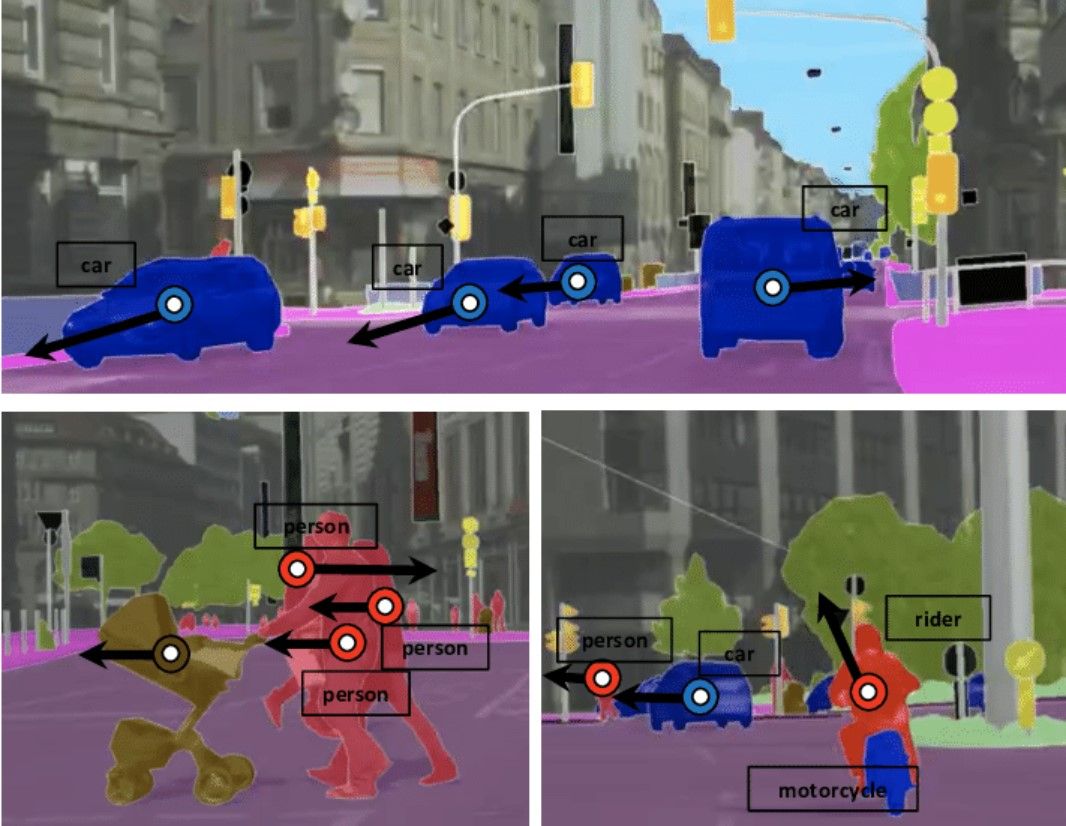
What kinds of data do autonomous vehicles use?
There are several devices and systems that can be used to create autonomous driving systems. These use a variety of technologies that can be annotated in real-time and beforehand. Each has a specific use case. Many have various forms of annotation that can be applied. The combinations of these sources, both during driving and in the design process are critical for the operation of these vehicles. Some of the most common forms of these data-analytical systems are:
- Sensors
- Video imagery
- Simulators
- Crowd-sourcing
Sensors can come in many forms and functions. For example, radar and lidar sensors can be used to determine the precise distance of external objects. Infrared devices can identify the unique heat signatures of pedestrians and other vehicles. Speedometers can ensure that cars are traveling at road-safe speeds. In each of these cases, the data gathered needs to be annotated such that they can construct a complete view of the world around these vehicles. It is this world that these cars drive through.
Video imagery also provides necessary context about the surroundings of these vehicles. They can help categorize what exactly these sensor-read items around the car are. The annotation will often rely on semi-automated tracking software to trace the movement of objects around the car. Oftentimes it will be layered with the information gathered from the sensors to generate an even more complete model of the world. The annotation process here will likely make use of AI-driven tracking software.
Simulators provide self-driving cars with data that might otherwise be dangerous or difficult to find. Many of these simulators are themselves generated using AI models of real-world environments. Simulating potential environments can prepare the vehicle for a huge number of possibilities – even those that would be rare in the real world. As an input, this opens up the applications of these vehicles far beyond what would naturally be contained in organic training data. Annotating simulated data will likely be a major part of any autonomous vehicle program.
Crowd-sourcing makes use of human drivers as examples of how vehicles should operate. Using a combination of sensors inside and outside of the vehicle, it can teach algorithms how to mimic the way that humans typically drive their vehicles. This is often the most basic kind of data used in autonomous driving. They align human responses with data collected about the vehicle's surroundings. This allows a model to be generated that can be generalized to the desired behaviors of vehicles. This relies on situational variety more than anything.
The challenges of autonomous driving data
The autonomous vehicle industry isn’t in its infancy any longer. The biggest challenge in constructing datasets for autonomous vehicles is the complexity of software. Human beings are notoriously bad at driving cars. Training vehicles to do the same will take on many of these human deficiencies. People are also less prone to trust machines capable of making errors. One faulty training dataset could set back the entire industry for months or years. This is why proper sourcing and annotation are so important.
The future of autonomous vehicles will generate massive amounts of data for other self-driving vehicles. This is one of the biggest benefits of this industry. What is meaningful data for one vehicle becomes meaningful for millions of other data-generating vehicles. Many imagine fleets of self-driving cars working together. This opens up endless new possibilities for how these cars will operate. Developing processes that can ensure all incoming data is properly annotated will be a major task of the industry in the coming years.



Comments ()